Executive Summary:
Before Investing in Enterprise Search, Invest in Maximizing Data Quality - this way you will get the most return form your investment!
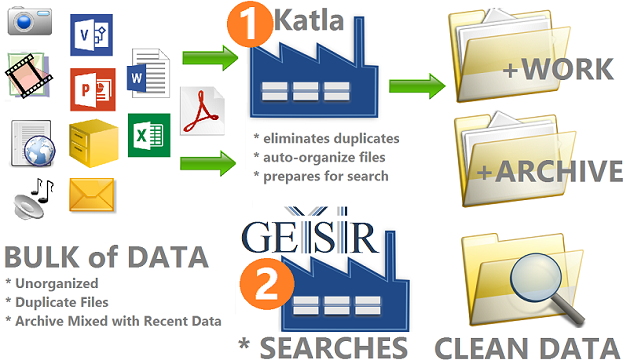
The above image is in fact a summary of this article and emphasizes that as Step #1, before Step #2 (which is Enterprise Search Implementation) companies should invest time in increasing Data Quality given that Data Quality impacts directly the success and return of investment in Enterprise Search Tools!
Any Enterprise Search Implementation should be treated as a separate Project.
A Project is: limited in time, has measurable results, has clear goals.
So how we measure the Success of an Enterprise Search Project Implementation?
Answer is: there are many variables here, but we will focus now on two:
- Recall - the fraction from ALL RELEVANT DOCUMENTS of RETURNED RESULTS
- Precision - the fraction from RETURNED RESULTS of RELEVANT RESULTS
In plain English -Recall is capacity of Search Engine to "Remember" all relevant documents relative to a user's query, while Precision is capacity to return a high concentration of relevant documents relative to user query. Higher the Recall and Precision the better!
So, a successful implementation of an Enterprise Search for a company can be measured by computing (for most important/often terms that employees are using in day-to-day operations) values of both Recall and Precision!
We at July Soft develop and implement GEYSIR Enterprise Search. We help companies to use their time, information and workforce more efficient and effective.
To see more details about benefits of Geysir you may visit this link.
Geysir's implementation success depends of its Recall and Precision - as mentioned before. But unfortunately those 2 variables are not only depending on our software's quality, they also depends heavily on input data quality!
Data quality can be drastically improved by:
- Eliminating Duplicated Files / Data
- Create Quality Meta-Data (implicit or explicit)
- Organize Data
- Eliminate old, useless data
- Etc
As we offer a limited GEYSIR Free Version you may request here, we also offer - FREE - July Soft KATLA File Organizer and Duplicate Removal Tool.
KATLA de-duplicate files, organizes data (Ex: split it between Archive and Working data, etc), creates implicit meta-data through data auto-organization, and more.
As the header image summarizes our point here, it worth, before investing in any Enterprise Search Implementation Project to increase Quality, Search-ability of data just to make sure Recall and Precision of implementation are highest possible thus maximizing the return of your investment and make your organization more efficient.
Note: If you are a technical person or willing to see more details and WHY eliminating duplicates increases Recall and Precision, you need to be at ease with following terms:
- Term Frequency
- Inverse Document Frequency
- TF-IDF Weighting
- You may do so while visiting this Wikipedia page.
If you want more details, we can show you at your email request at iulia@runbox.com a free live Geysir demo by Skype for about 1 hour.
For a better search,
July Soft Team - www.julysoft.net
Responsibility. Integrity. Passion.